Appearance
GPU侧的性能优化
一般提起GPU的优化,往往会谈到很多词,诸如合批、drawcall等等,这里的情况比较多,我们先描述一个场景,然后由此入手。
渲染的过程是把CPU侧的内容(模型、材质、绘制方式等)准备成GPU可以理解的形式,然后传输到GPU,等GPU绘制完成之后,再把下一帧的内容,再给到GPU绘制,一帧一帧的循环往复,形成画面。GPU利用其并行化的能力,批量的进行顶点变换,光栅化,着色,完成物体的绘制。
那么在这段话里面就会有几个节点需要我们关注。
最小化更新:CPU准备好的东西上传GPU后,会在显存中保存形成句柄,下次如果没有变化不需要再上传(不需要再打扰这个句柄),也就是最小化更新。
- 最小化更新已经再引擎底层做了实现,但业务侧依然需要有所感知,如相机移动的时候,将一些物体反复的设置visible为true或false,使得底层反复的组织渲染队列。正确的做法是不去破坏渲染队列,而是做额外标记,由引擎底层去组织是否显示。类似给一个Dom对象设置display为none,还是设置visibility为hidden,还是把这个dom从document中删除,那种情况最好?
- 还有一个值得注意的情况就是,CPU与GPU发起交互,请求交互的过程是慢的,一旦建立连接,传输1k的数据还是1M的数据所差的性能相差无几,所以无论是渲染状态还是buffer,都应该做到最小化,这部分在引擎底层已经进行了保证,而对于下一代API的帧内容重播更要求这样,已经录好的指令就别变来变去,要求渲染队列稳定。
批次合并:尽可能少的渲染对象,以为GPU的并行化能力很强大,但是给过来的都是小对象,就是串行逐个处理每个三角面片也慢不到哪里去,刚启动就停下来重新装载下一个模型到上下文,所以需要合并批次,将小对象合并成大对象,让GPU的并行能力得到充分发挥。把一个渲染对象的完整执行过程叫一个drawcall,应该尽量的减少drawcall。引擎底层已经有几种策略来进行批次合并的操作。但是奇怪在哪里呢,就是业务侧也会进行批次合并,但是又合并不完全还是很散。但因为合并过,所以无法遵循底层触发合并的条件,所以拖慢性能。
CPU与GPU的协同:CPU在将当前帧数据提交给GPU后就可以立刻开始下一帧的更新,组织下一帧的渲染数据了,这个时候GPU也同时去渲染当前帧的数据,最好的情况是GPU渲染完当前帧数据,CPU也准备好下一帧的数据了,二者充分协同不等待,最大化把硬件充分的利用起来。然而事实的情况根本不是这样,有人配的电脑就是一个垃圾小显卡加一个2K大屏幕,或者高性能GPU配一个低功耗CPU。也有使用场景的原因,就是没什么业务逻辑但需要绘制一个超级大的场景,或者非常重度的CPU业务但什么东西需要绘制。这两类原因加起来,总是不平衡的。不平衡的出现会导致一方等待另外一方,帧率是由双方决定的。
- 有人说拾取使用GPU进行拾取会比CPU拾取更快,或者说看这段逻辑有并行化的可能,放到GPU上去搞吧,解放CPU。解放CPU干嘛呢,说不定GPU要累死了,CPU没事做呢,还把工作给GPU。要的是二者协同,而不是想当然的去优化。
- 另外对于打断渲染流的业务操作应该避免或异步,比如保存截图的操作,CPU组织数据给GPU渲染,GPU渲染的时候CPU本来是可以组织下一帧数据的,但是因为要获取渲染的结果,那么就迫使cpu等待在那里,没有做下一帧数据准备的动作,也就是人为的打断二者的协同。保存截图是一个低频操作,高频操作就是GPU拾取,每帧都拾取,等GPU的结果来判断选中了哪个物体在去做业务逻辑。GPU拾取是有应用场景限制的,这个限制就是GPU能够很快的完成工作,并且在显示屏幕刷新率之间的时间内完成,完全不抢占CPU工作的时间。但因为其打断二者协同的性质,在GPU重度的场景中,不适用。
- Profile初步
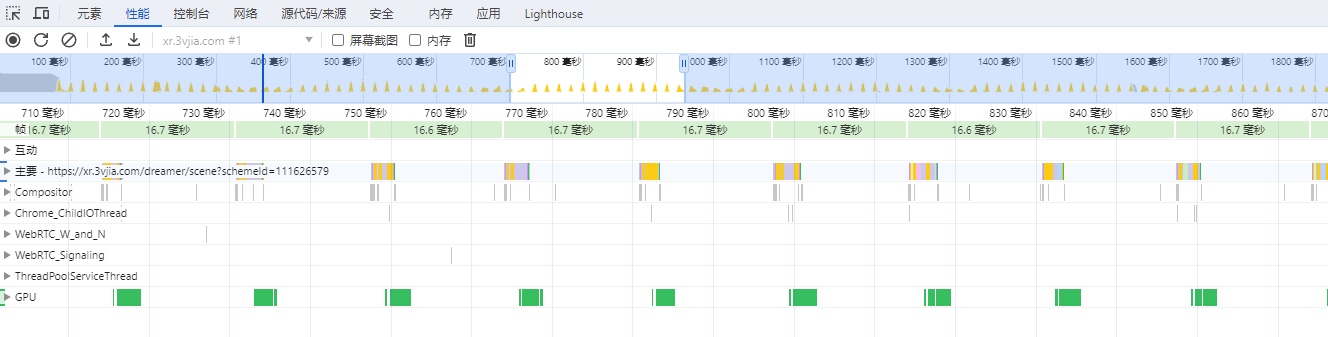
- 这幅图为Chrome的profile的截图,这个截图也描述了CPU和GPU的协同关系。浏览器对应用程序的update的时机,就是屏幕的刷新频率,如60赫兹就是每秒调用60次,用于CPU组织数据并送到GPU渲染,从渲染的角度来讲没有必要超出显示器的刷新频率。
- 黄色的部分是CPU的占用,绿色的部分是GPU的占用。当GPU吃满时,绿色将连城一片而黄色部分有间隔;当CPU吃满时黄色部分连城一片而绿色部分有间隔。
GPU渲染管线中的不同阶段。
- 顶点着色器:往往是顶点数太多,导致GPU的使用率吃满,在这种情况下只能降低渲染的三角面数量,比如通过裁剪的方式,通过应用场景的方式,通过MeshLod的方式等。
- 像素着色器:shader指令过多,纹理过大等因素。
- 一般往往会强调shader的复杂程度,但是随着GPU的发展这部分的情况越来越好,比如for循环、if分支带来的性能降低,在当前主流的GPU中都不再成为问题,加上shader在编译的时候会使用语法树对其进行优化,几乎可以忽略这部分的性能影响。
- 纹理过大时一个因素,比如1024的纹理和超出1024的问题,在一些既定的GPU会明显感觉到帧率的下降,我个人猜想纹理采样的时候也是要对纹理的buffer进行吞吐的,一旦buffer过大,一次吞吐不完,要迭入迭出,那么性能就会明显下降。
- 这里再说明一个问题,GPU有没有像CPU那样的缓存呢?是有的,但是和CPU的高速缓存有很大区别,对应软件工程师来讲不需要关注这部分内容。软件工程师关注的是一些外围内容,如关于读取:纹理>uniform>SSBO,尤其是对于大量的只读对象,upload到纹理会提升些许性能。诸如此类。
- 再实际的项目中,很少有项目因为shader写的太复杂导致卡顿(主要是自身能力决定,写不出来那么复杂的公式),大多数是卡在因为三角面片太多、纹理太大导致的卡顿。
下一代渲染API能否带来性能提升?
- 下一代渲染API是指Vulkan、Metal、WebGPU等,开放了更多的GPU硬件特性给软件工程师控制,而不是由硬件工程师承担。所以要求使用的团队有一个更聪明的程序员。
- 下一代渲染API释放的是CPU的生产力而不是GPU的生产力。GPU的生产力是硬件本身决定的,多少渲染核心或者模块布置等等,也就是说对于因三角面过多而产生性能下降是无能为力的,上到GPU的大量的三角面和顶点就是这么多,GPU处理吧,不可能因为使用下一代的API,哪怕下下一代的API驱动,GPU就爆发了洪荒之力。
- 解放CPU的生产力是指,因为软件工程师有更多的硬件控制权,所以可以根据实际的情况,甚至根据项目的特有情况,来进行硬件控制,使得传输的数据更小,更有条理等等,实际上也就是提升在这里。老的API是硬件工程师封装的,通杀所有情况;下一代api是软件工程师封装的,可服务于特定情况。当然这个软件工程师得行,要不然性能会更差,这个是真实的情况。
批次和三角面综合考虑:以下是某项目某次实验结果,具体的测试环境和场景忽略。
- 批次为1000,700w三角面和20w三角面,帧率一致。即批次多的时候,无论再怎么压降三角面都没有办法提升帧率。
- 三角面为1500w,100批次和1000批次一样。无论怎么合批都没办法提升帧率。
以上从感性的方面,大概的介绍了GPU的各个方面,针对这些方面会衍生一些优化的手段和技术。在文档的各个章节会有一定的介绍,大家可以关注这些部分的内容。